Problem
At my current job each team has a dev(n)-stage(n)-production(n) type deployment workflow. Application deployments are kept in git repositories and deployed by our continuous delivery tooling.
It is unusual for there to be major differences between applications deployed to each of these different contexts. Usually it is just a matter of tuning resource limits or when testing, deploying a different version of the deployment.
The project matrix looks like this:
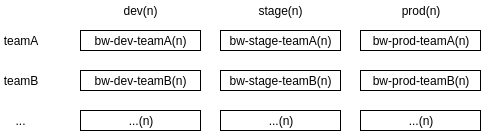
GCP projects must have globally unique names, so ours are prefixed with “bw-“
The directory structure is composed of Names, Deployments, and Components:
- Name is the GCP Project name
- A Deployment is a logical collection of software
- A Component is a logical collection of Kubernetes manifests
For example, a monitoring deployment composed of influxdb, grafana, and prometheus might look like:
monitoring/prometheus/<manifests>
monitoring/influxdb/<manifests>
monitoring/grafana/<manifests>
The monitoring stack can be deployed to each context by simply copying the monitoring deployment to the relevant location in our directory tree:
bw-dev-teamA0/monitoring/
bw-stage-teamA0/monitoring/
bw-prod-teamA0/monitoring/
bw-dev-teamB0/monitoring/
bw-stage-teamB0/monitoring/
bw-prod-teamB0/monitoring/
In order to apply resource limits for the stage and prod environments where teamB processes more events than teamA:
bw-dev-teamA0/monitoring/prometheus/ #
bw-dev-teamA0/monitoring/influxdb/ # unchanged
bw-dev-teamA0/monitoring/grafana/ #
bw-stage-teamA0/monitoring/prometheus/ # cpu: 1, mem: 256Mi
bw-stage-teamA0/monitoring/influxdb/ # cpu: 1, mem: 256Mi
bw-stage-teamA0/monitoring/grafana/ # cpu: 1, mem: 256Mi
bw-prod-teamA0/monitoring/prometheus/ # cpu: 1, mem: 256Mi
bw-prod-teamA0/monitoring/influxdb/ # cpu: 1, mem: 256Mi
bw-prod-teamA0/monitoring/grafana/ # cpu: 1, mem: 256Mi
bw-dev-teamB0/monitoring/prometheus/ #
bw-dev-teamB0/monitoring/influxdb/ # unchanged
bw-dev-teamB0/monitoring/grafana/ #
bw-stage-teamB0/monitoring/prometheus/ # cpu: 1, mem: 256Mi
bw-stage-teamB0/monitoring/influxdb/ # cpu: 1, mem: 256Mi
bw-stage-teamB0/monitoring/grafana/ # cpu: 1, mem: 256Mi
bw-prod-teamB0/monitoring/prometheus/ # cpu: 2, mem: 512Mi
bw-prod-teamB0/monitoring/influxdb/ # cpu: 2, mem: 512Mi
bw-prod-teamB0/monitoring/grafana/ # cpu: 2, mem: 512Mi
To also test a newer version of influxdb in teamA’s dev environment:
bw-dev-teamA0/monitoring/prometheus/ #
bw-dev-teamA0/monitoring/influxdb/ # version: 1.4
bw-dev-teamA0/monitoring/grafana/ #
bw-stage-teamA0/monitoring/prometheus/ # cpu: 1, mem: 256Mi
bw-stage-teamA0/monitoring/influxdb/ # cpu: 1, mem: 256Mi
bw-stage-teamA0/monitoring/grafana/ # cpu: 1, mem: 256Mi
bw-prod-teamA0/monitoring/prometheus/ # cpu: 1, mem: 256Mi
bw-prod-teamA0/monitoring/influxdb/ # cpu: 1, mem: 256Mi
bw-prod-teamA0/monitoring/grafana/ # cpu: 1, mem: 256Mi
bw-dev-teamB0/monitoring/prometheus/ #
bw-dev-teamB0/monitoring/influxdb/ # unchanged
bw-dev-teamB0/monitoring/grafana/ #
bw-stage-teamB0/monitoring/prometheus/ # cpu: 1, mem: 256Mi
bw-stage-teamB0/monitoring/influxdb/ # cpu: 1, mem: 256Mi
bw-stage-teamB0/monitoring/grafana/ # cpu: 1, mem: 256Mi
bw-prod-teamB0/monitoring/prometheus/ # cpu: 2, mem: 512Mi
bw-prod-teamB0/monitoring/influxdb/ # cpu: 2, mem: 512Mi
bw-prod-teamB0/monitoring/grafana/ # cpu: 2, mem: 512Mi
The point of this example is to show how quickly maintenance can become a problem when dealing with many deployments across multiple teams/environments.
For instance, this example shows that five unique sets of manifests would need to be maintained for this single deployment.
Solution
Requirements
- Deploy different versions of a deployment to different contexts (versioning)
- Tune deployments using logic and variables based on deployment context (templating)
Versioning
Let’s say we want to have the following:
bw-dev-teamA0/monitoring/prometheus/ #
bw-dev-teamA0/monitoring/influxdb/ # version: 1.4
bw-dev-teamA0/monitoring/grafana/ #
bw-stage-teamA0/monitoring/prometheus/ #
bw-stage-teamA0/monitoring/influxdb/ # version: 1.3
bw-stage-teamA0/monitoring/grafana/ #
bw-prod-teamA0/monitoring/prometheus/ #
bw-prod-teamA0/monitoring/influxdb/ # version: 1.3
bw-prod-teamA0/monitoring/grafana/ #
bw-dev-teamB0/monitoring/prometheus/ #
bw-dev-teamB0/monitoring/influxdb/ # version: 1.3
bw-dev-teamB0/monitoring/grafana/ #
bw-stage-teamB0/monitoring/prometheus/ #
bw-stage-teamB0/monitoring/influxdb/ # version: 1.3
bw-stage-teamB0/monitoring/grafana/ #
bw-prod-teamB0/monitoring/prometheus/ #
bw-prod-teamB0/monitoring/influxdb/ # version: 1.3
bw-prod-teamB0/monitoring/grafana/ #
This can be achieved by creating directories for each version of the deployment:
/manifests/monitoring/0.1.0/ # contains influxdb version 1.3
/manifests/monitoring/0.2.0/ # contains influxdb version 1.4
/manifests/monitoring/latest -> 0.2.0 # symlink to latest version (used by dev environments)
And then by quite simply symlinking the deployment to the version to deploy:
bw-dev-teamA0/monitoring/ -> /manifests/monitoring/latest # deployment version 0.2.0
bw-stage-teamA0/monitoring/ -> /manifests/monitoring/0.1.0
bw-prod-teamA0/monitoring/ -> /manifests/monitoring/0.1.0
bw-dev-teamB0/monitoring/ -> /manifests/monitoring/0.1.0
bw-stage-teamB0/monitoring/ -> /manifests/monitoring/0.1.0
bw-prod-teamB0/monitoring/ -> /manifests/monitoring/0.1.0
Although this solves the versioning problem, this doesn’t help with customizing the deployments, which is where templating comes in.
ERB and Hiera
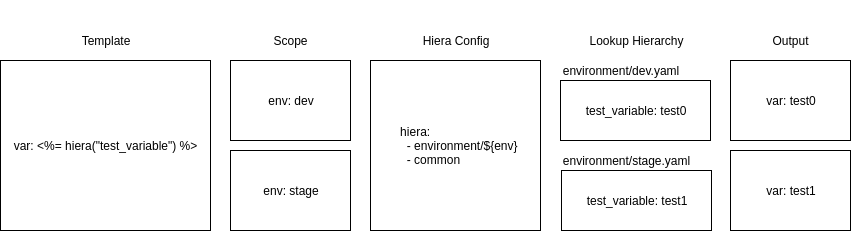
Understanding ERB and Hiera is beyond the scope of this article but this diagram should give some clue as to how they work.
Templating
erb-hiera is a generic templating tool, here’s an example of what a config to deploy various versions of a deployment to different contexts looks like:
- scope:
environment: dev
project: bw-dev-teamA0
dir:
input: /manifests/monitoring/latest/manifest
output: /output/bw-dev-teamA0/cluster0/monitoring/
- scope:
environment: stage
project: bw-stage-teamA0
dir:
input: /manifests/monitoring/0.1.0/manifest
output: /output/bw-stage-teamA0/cluster0/monitoring/
- scope:
environment: prod
project: bw-prod-teamA0
dir:
input: /manifests/monitoring/0.1.0/manifest
output: /output/bw-prod-teamA0/cluster0/monitoring/
- scope:
environment: dev
project: bw-dev-teamB0
dir:
input: /manifests/monitoring/0.1.0/manifest
output: /output/bw-dev-teamB0/cluster0/monitoring/
- scope:
environment: stage
project: bw-stage-teamB0
dir:
input: /manifests/monitoring/0.1.0/manifest
output: /output/bw-stage-teamB0/cluster0/monitoring/
- scope:
environment: prod
project: bw-prod-teamB0
dir:
input: /manifests/monitoring/0.1.0/manifest
output: /output/bw-prod-teamB0/cluster0/monitoring/
Note that instead of having a complex and difficult to manage directory structure of symlinks the input directory is defined in each block - in this example the input directories are versioned, as discussed in the Versioning section
Example hiera config:
:backends:
- yaml
:yaml:
:datadir: "hiera"
:hierarchy:
- "project/%{project}/deployment/%{deployment}"
- "deployment/%{deployment}/environment/%{environment}"
- "common"
Now it is possible to configure some default resource limits for each environment. It is assumed stage and prod require roughly the same amount of resources by default:
deployment/monitoring/environment/stage.yaml:
limits::cpu: 1
limits::mem: 256Mi
deployment/monitoring/environment/prod.yaml:
limits::cpu: 1
limits::mem: 256Mi
Then override team B’s production environment to increase the resource limits, since it needs more resources than the other environments:
project/%{project}/deployment/monitoring.yaml:
limits::cpu: 2
limits::mem: 512Mi
One more change is required in order for this configuration to work. It is necessary to wrap the limits config in a condition so that no limits are applied to the dev environment:
<%- if hiera("environment") =~ /stage|production/ -%>
apiVersion: v1
kind: LimitRange
metadata:
name: limits
spec:
limits:
- default:
cpu: <%= hiera("limits::cpu") %>
memory: <%= hiera("limits::mem") %>
...
<% else %>
# no limits set for this environment
<% end %>
The result is that with a simple erb-hiera config, hiera config, hiera lookup tree, and versioned manifests, the desired configuration described earlier is reached with less code duplication.
Why Not Helm?
Helm can be used in various different ways, it can do as much or as little as required. It can act in a similar way to erb-hiera by being used simply to generate manifests from templates, or act as a fully fledged release manager where it deploys a pod into a kubernetes cluster which can track release state for the deployed helm charts.
So why erb-hiera? Because it is simple, and our teams are used to the combination of ERB templating language and Hiera due to their familiarity with Puppet. We can use the same tool across multiple code bases which manage our infrastructure and applications.
If you like Hiera but prefer Go templates, perhaps developing a Hiera plugin for Helm would be a good option?
erb-hiera can be used to manage all Kubernetes manifests but it is also entirely possible to use helm in parallel. At the moment we have a combination of native kubernetes manifests, helm charts, and template generated documents from erb-hiera.
Conclusion
erb-hiera is a simple tool which does just one thing: document generation from templates. This article has shown one possible use case where using a templating tool can be combined with versioning to provide powerful and flexible Kubernetes manifest management.